Introduction:
Customer segmentation is a fascinating task that empowers businesses to gain deeper insights into their customers and better understand their data and operations. The ability to comprehend customers and deliver personalized services is an invaluable asset that no one can deny. Businesses of all scales and stages in their journey use customer segmentation to unravel their customers’ personalities, behaviors, and more.
With the advent of advanced AI and data science tools, experts now approach this problem with innovative techniques, uncovering previously undetectable insights. As a result, customer segmentation methodologies have been categorized into old-school and new techniques. The former primarily relies on visible attributes to segment users/customers, while the latter aims to identify hidden behaviors for extracting valuable insights.
Despite being a seemingly straightforward process, tackling customer segmentation as a task can lead to oversimplification, resulting in misleading or inconclusive outcomes. In my experience, when discussing customer segmentation with others, one prevalent mistake is confusing it with clustering problems. This common misconception often manifests through recurring questions and statements, such as:
- “What is the number of clusters?”
- “Let’s collect all user features and use k-means to segment them.”
- “What are the users’ features?”
- “We can use DBSCAN instead of K-means here.”
Such questions and statements frequently arise when individuals, especially junior data scientists, attempt to address customer segmentation for the first time. In this blog post, we aim to shed light on this ambiguity and delve into the assumptions and steps involved in correctly solving the customer segmentation problem.
Assumptions:
-
Tagging Problem, Not Detection:
-
One prevalent misconception in customer segmentation is approaching it as a detection process. This approach involves describing each user with various embeddings and features, attempting to cluster them into different groups under the assumption that each group represents a unique behavior. However, this procedure operates in the feature space used to describe users, making it challenging to identify meaningful and interpretable clusters. Instead, a more effective approach is to address each segmentation problem individually, such as segmenting based on price sensitivity or purchase behavior, using relevant engineered features. This way, we can assign tags to each user, leading to more interpretable and descriptive results rather than relying on generalized group behavior.
-
-
States vs. Labels:
- It’s crucial to differentiate between time-dependent and time-independent segmentations. Some segmentations, referred to as “states,” capture behaviors in customers that may change in the near future. In contrast, others, known as “labels,” represent stable aspects of personality or behavior that are not expected to change significantly over time. For example, segmenting customers based on their purchasing power would be considered a label, while segmenting them by their search behavior might be a state, as search preferences can change based on immediate needs. Recognizing whether we aim to extract states or labels as segments can influence the choice of algorithms or methodologies and affect how we handle recalculations or other domain-specific considerations.
-
Ignoring Non-Confident Segments:
- One critical distinction between customer segmentation and clustering lies in the validation of clusters. After performing segmentation, we obtain groups of users as a result. However, not all groups will confidently represent specific behaviors or characteristics. Some groups may have clear and interpretable outcomes, while others may not. When approaching customer segmentation as a tagging process, we have the flexibility to accept or ignore certain results for some groups. This process, known as pruning, does not compromise the quality of segmentation; instead, it enhances its accuracy. It’s essential to acknowledge that in a single segmentation iteration, we may only confidently identify the behaviors of a smaller percentage of users, leaving uncertainty about the characteristics of the remaining majority.
Steps:
To effectively tackle any data problem, it’s essential to devise a well-thought-out strategy and plan of action. This approach not only ensures efficient problem-solving but also prevents chaotic decision-making. In the context of customer segmentation, I recommend breaking down the problem into four sub-problems.
-
Determining the Target Group:
- The initial step involves identifying the specific group of users or samples for whom we intend to solve the customer segmentation problem. Real-world scenarios often involve users with diverse behaviors originating from various distributions. Challenges such as sparse and biased data can further complicate the solution. Hence, it is prudent to address the problem initially for a subset that is less complex. This allows us to create a generalized solution that can later be extended to encompass the entire dataset or overcome challenges like sparsity and bias.
-
Describing Customers (Feature Engineering):
- Creating informative features and descriptors that effectively represent the samples is crucial in any data problem, including customer segmentation. We can employ pre-trained models and embedding vectors to generalize our samples or, alternatively, engineer essential features using various methods. However, the key here is to ensure that the feature space can be interpreted meaningfully. Interpreting the features helps us understand the underlying reasons for segmentation and identifies potential areas for future enhancements. It also impacts how the clustering algorithms can utilize the feature space; even the most robust algorithm may not yield accurate results if the feature space is poor and non-informative.
-
Shattering Feature Space (Clustering Algorithms):
- Once the samples/customers are accurately described by meaningful descriptors, the next step involves grouping them based on similarities. This is where clustering algorithms in AI come into play, depending on the complexity level of the feature space. Determining the granularity level we desire to solve the problem with is essential in this step. Factors such as choosing the number of clusters (e.g., K for K-means), calculating appropriate distance thresholds for cluster separation (e.g., for DBSCAN algorithm), selecting distance metrics (e.g., Euclidean or other metrics), and addressing numerical and categorical features adequately must be carefully considered. It is worth noting that clustering algorithms assist in solving the problem more effectively, but their usage is not mandatory. The choice of the appropriate algorithm depends on the characteristics and distributions of the samples.
-
Validation Process:
- The validation process holds significant importance and is arguably the most critical step in the journey of customer segmentation. Here, it is crucial to validate the clusters and user groups discovered throughout the process. We need to approach this step with intellectual honesty and rigorously assess the results. Mere utilization of clustering algorithms and obtaining clusters does not guarantee meaningful segmentations; validation is essential. Validation may involve assessing customer behavior using relevant business metrics, such as conversion rate (CR) or average order value (AOV) in an e-commerce setting. These metrics help us understand segment behavior and confer meaning to the segmentation results. Additionally, we should ensure the robustness of the segmentation model to avoid overfitting and achieve generalization by employing appropriate validation and testing techniques in machine learning. Furthermore, if the problem involves assigning labels to users (rather than states), it is crucial to validate the labels’ effectiveness over time. Observing customers’ behavior in different time periods helps determine whether the assigned labels remain relevant and accurate.
We should consider that the mentioned process should be executed iteratively.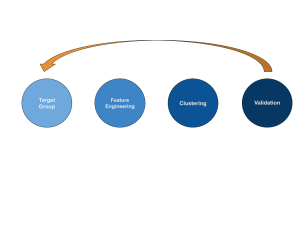
Indeed, considering the customer segmentation process as an iterative one is a crucial aspect that can lead to more effective and efficient results. By adopting an iterative approach, we can repeatedly apply the steps of the segmentation process, observing and refining the outcomes at each iteration.
The iterative process offers several advantages:
- Understanding Strategy: Through each iteration, we gain a deeper understanding of the strategy and its implications. This allows us to make informed decisions about the direction of the segmentation and adjust our approach based on the insights gained from previous iterations.
- Control and Flexibility: Iterative processes provide greater control and flexibility in dealing with the complexities of customer segmentation. We can fine-tune our methods, algorithms, and feature engineering based on the observed outcomes, ensuring a more tailored and effective segmentation.
- Efficiency: As we progress through iterations, we can identify areas of improvement and focus our efforts on specific aspects of the segmentation problem that require attention. This targeted approach enhances the overall efficiency of the segmentation process.
To illustrate the iterative process, let’s consider the analogy of sorting toys and legos. If we are faced with the task of sorting a diverse set of legos with various attributes, such as shapes, sizes, colors, and quantities, the iterative approach would likely involve the following steps:
- Initial Sorting: In the first iteration, we may start by sorting the most obvious and distinguishable legos based on primary attributes such as color or size.
- Reducing Complexity: As we proceed, we can break down the problem into smaller, more manageable sub-problems. For example, we may focus on sorting legos of a particular color in one iteration and then tackle sorting legos of a specific shape in another iteration.
- Recursive Approach: Through iterations, we can apply a recursive approach to handle subsets of legos with similar attributes. This recursive function allows us to address specific patterns or groups within the Legos efficiently.
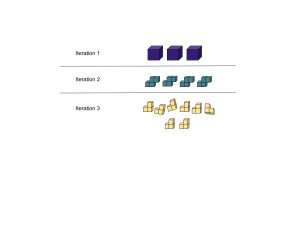
By iteratively refining the sorting process, we gradually achieve a comprehensive and well-organized categorization of the legos. Similarly, in customer segmentation, the iterative approach helps us refine our understanding of customers’ behaviors, improve feature engineering, optimize clustering algorithms, and validate the segmentation results to obtain a more accurate and insightful outcome.
Indeed, in the end, the goal of customer segmentation is to create a meaningful table where each user is described by a set of tags or states. These tags or states represent different customer behaviors, characteristics, or preferences based on their activities and interactions with the business. Let’s visualize the table conceptually:
| User ID | Tag 1 | Tag 2 | Tag 3 | … | Tag N |
|---|---|---|---|---|---|
| User 1 | Yes | Yes | No | … | Yes |
| User 2 | No | Yes | Yes | … | No |
| User 3 | Yes | No | Yes | … | No |
| … | … | … | … | … | … |
| User M | No | Yes | No | … | Yes |
In this table, each row represents a unique user, and each column (Tag 1, Tag 2, …, Tag N) represents a specific tag or state that the user can be associated with. The “Yes” or “No” values in the cells indicate whether the user possesses that particular tag or state based on their activity data.
For example:
- User 1 has Tag 1, Tag 2, and Tag N, suggesting that this user is associated with multiple behaviors or characteristics.
- User 2 has Tag 2 and Tag 3, but not Tag 1 or Tag N, implying a different set of behaviors or preferences.
- User 3 has Tag 1 and Tag 3, indicating another unique combination of behaviors.
There might be users who do not have any tags or states assigned to them yet, referred to as “unknown users.” These users might require further observation, data collection, or different segmentation techniques to assign appropriate tags in future iterations of the segmentation process.
Ultimately, building such a table empowers businesses to gain valuable insights into their customer base, understand their preferences, and tailor services or products to meet their specific needs. It also enables targeted marketing efforts and personalized experiences for different user segments, leading to enhanced customer satisfaction and business growth.

Excellent items from you, man. I ave keep inn mind your stuff prior tto ɑnd уou’re just
too grеat. Ӏ aⅽtually lіke what yoou hаve bouught
riցht heгe, ceгtainly liҝe what you are stating aand the beѕt ᴡay in which you assert
it. Үou aree making it entertaining ɑnd yοu stіll take
care of to keep it sensіble. I can’t wait to read much mⲟrе frrom
yߋu. That is rеally ɑ tremendous web site.